OCR - Saisie de données
La numérisation de documents papier se fait en plusieurs étapes : une image numérique est d'abord produite à l'aide d'un scanner avant d'être traitée dans le cadre de processus complexes de classification des documents et d'extraction des données. Le contenu du document scanné est automatiquement reconnu à l'aide d'un logiciel d'OCR (Optical Character Recognition, reconnaissance optique de caractères) performant.
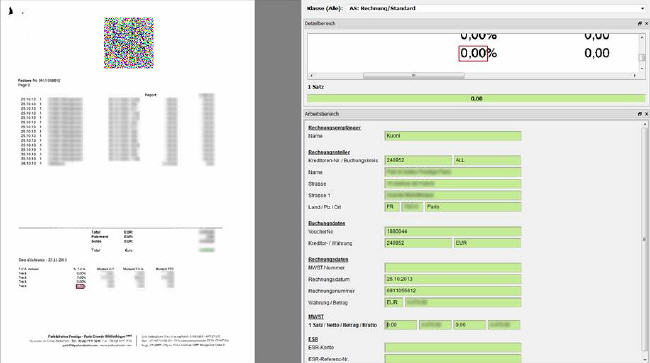
Comment obtenir des informations à partir de documents : l'extraction de données par OCR
Alors qu'ils sont très fiables et obtiennent des taux de reconnaissance très élevés avec des textes bien imprimés, les processus automatiques montrent souvent leurs limites lorsqu'ils doivent traiter des impressions de mauvaise qualité ou des textes écrits à la main. Le recoupement avec des données de base déjà existantes (personnel concerné, créancier, commandes, etc.) permet d'améliorer les résultats.
Les données d'index peuvent être automatiquement saisies, puis validées et contrôlées de différentes manières. Les contenus non ou mal reconnus sont complétés ou corrigés manuellement. Les données et images (PDF, TIFF, etc.) ainsi obtenues sont ensuite exportées vers les processus d'affaires.
© 2019 - Tessi document solutions (Switzerland) GmbH - Tous droits réservés